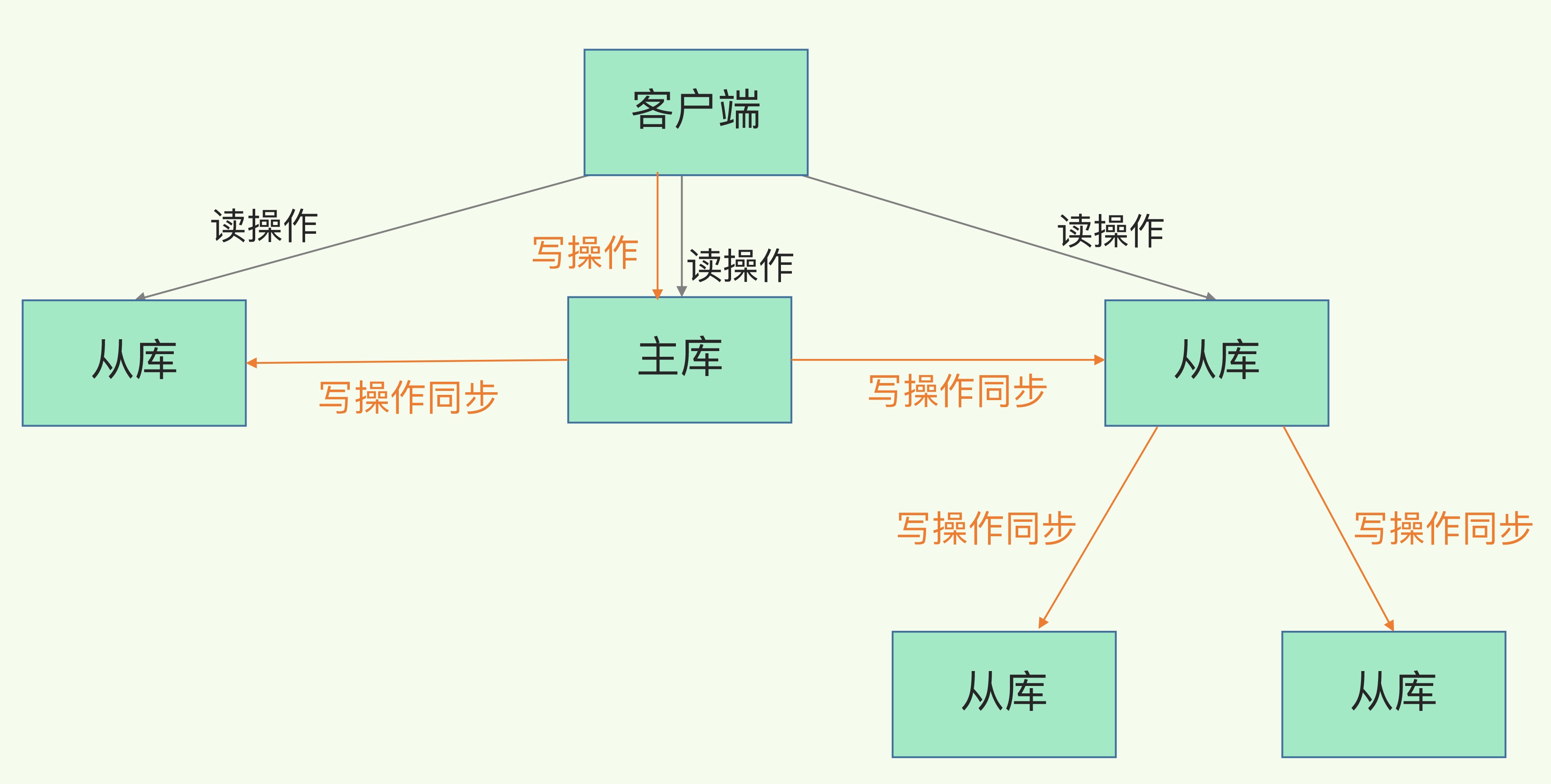
Redis 的高可靠性通过减少数据的丢失,以及减少服务的中断实现,为保证减少数据的丢失通过AOF和RDB 保证,而减少服务中断通过增加副本冗余保证;Redis 提供了主从模式,保证数据副本的一致,主从库之间使用读写分离;对于读操作,主从都可接受,而写操作则首先主库执行然后同步到从库
从主第一个次同步
Redis 多个实例之间可以通过replicaof 命令 (5.0 之前slaveof)形成主库和从库。

第一阶段
主从库之间建立连接,协商同步的过程,为全量同步做准备。从库和主库之间建立连接,并与主库通信将要开始同步,主库确认恢复后,主从之间可以进行同步。
- 从库给主库发送 psync 命令,表示要进行同步,主库根据 psync 来启动复制,此时不知道从库的runID 设置为'?',offset 设置为 -1,表示第一次复制
- 主库收到 psync 命令后,使用 FULLRESYNC 带两个参数 主库runID和主库目前的offset,返回给从库,从库收到响应后记录两个参数
第二阶段
主库将所有的数据发送给从库,从库收到数据后在本地完成数据的加载。这个过程依赖于RDB文件
- 主库还行 bgsave 命令,生成RDB文件,接着将文件发送给从库
- 从库收到RDB文件后,先清空当前数据库,然后加载RDB文件
- 主库保存RDB文件生成后所有的写命令在内存中的replication buffer中
第三阶段
主库把replication buffer中的修改操作送给从库,从库再重新执行这些操作
主从级联模式
在部署主从集群的时候,可以手动选择一个从库,用于级联其他从库。这样这些从库不再和主库进行同步,而是和级联的从库进行写操作同步。
主从风险
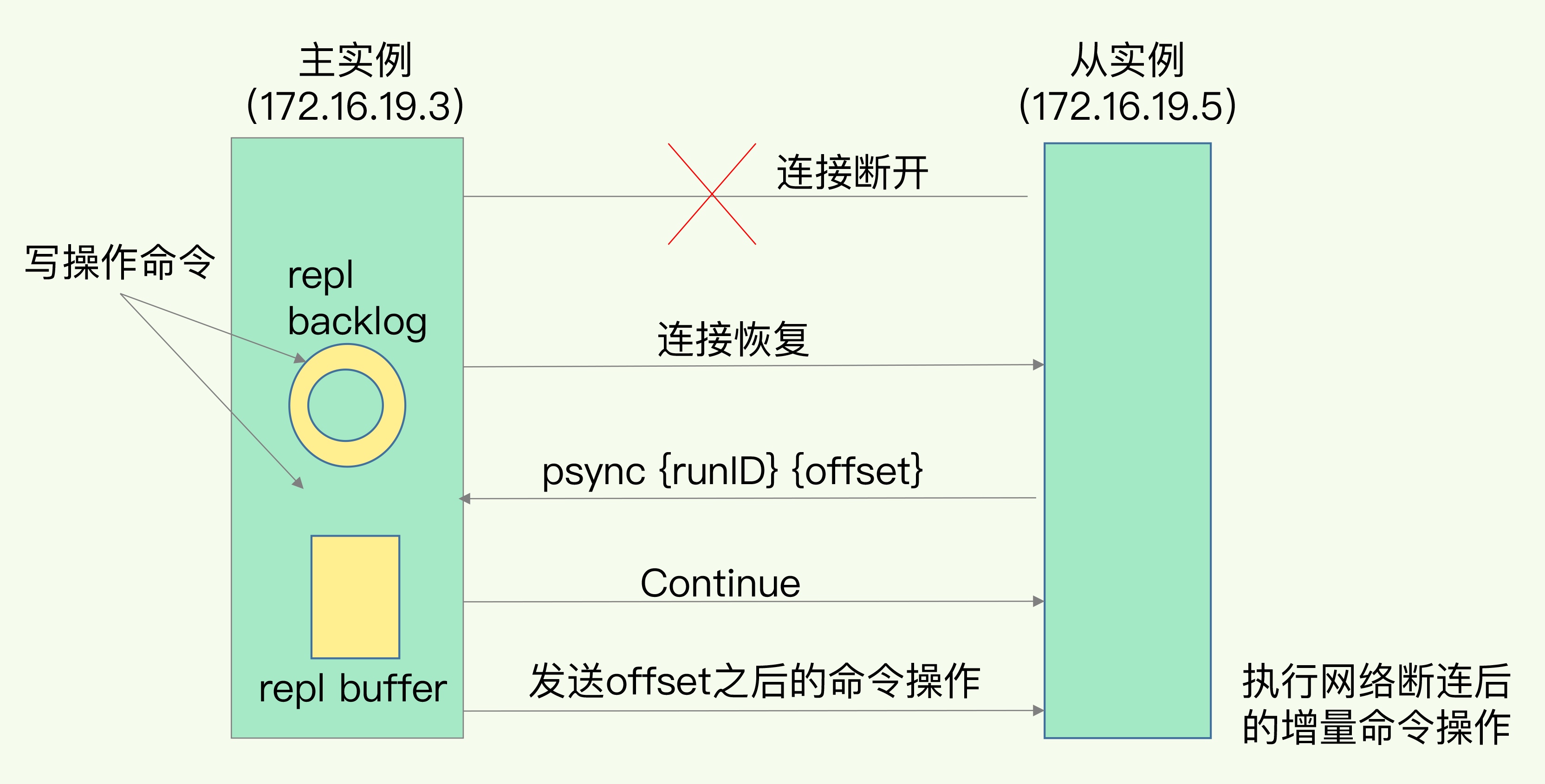
主从是基于长连接的命令传播,如果网络断连那么主从之间就无法进行命令传播,会导致主从不一致
网络断连
- 2.8 之前出现网络断连后会执行一次全量同步
- 2.8 之后进行增量同步
增量同步
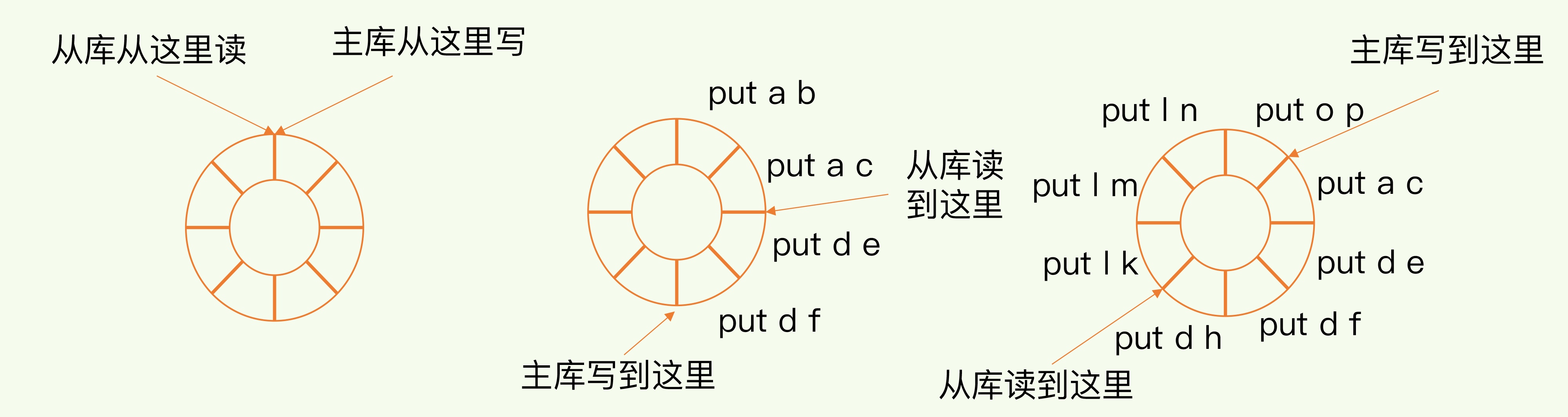
主库会把断期间的写操作写入replication buffer ,同时把这些命令写入到 repl_backlog_buffer, repl_backlog_buffer 是一个环形缓存区,主库会记录自己写的位置,从库会记录读的位置。主库通过master_repl_offset 记录写的偏移量,从库通过 slave_repl_offset 记录读的偏移量
增量流程
从库读取数据速度比较慢,导致主库的写覆盖repl_backlog_buffer。导致主从不一致,通过repl_backlog_size控制。
